随着机器学习渗透到社会,科学家们正试图帮助防范不公正。
2015年,一位忧心忡忡的父亲问了一个至今仍在Rhema Vaithianathan心头盘桓的问题。那天几个人聚集在匹兹堡的一间地下室,听Vaithianathan解释软件可以如何解决儿童虐待问题。
每天,这片区域的热线都会接到数十通怀疑儿童处于危险中的电话;之后,部分电话会被中心工作人员标记出来,进行调查。但这一系统并不能发现所有虐童事件。那时,Vaithianathan和同事刚拿下50万美元的合同,合同内容是搭建一套算法来解决这问题。

Mario Wagner
Vaithianathan是一名卫生经济学家,也是奥克兰理工大学社会数据分析中心的联合主管。她对几位听众解释了算法该如何运作。比方说,在接到电话的时候,一套经过大量数据(包括家庭背景和犯罪记录)训练的工具可以进行风险评分,帮助工作人员标记需要调查的家庭。
在Vaithianathan邀请听众提问时,这位父亲站起来开口了。他说自己曾经有毒瘾,一个孩子已经被社工从家里带走,但在那之后他已经不再碰毒品,如果让计算机来评估他的记录,那么他的改过自新是否只是白费?换句话说,算法能对他做出公正的判断吗?
Vaithianathan向他保证,永远会有人工参与其中,这样他所付出的努力就不会被忽视。但现在自动工具已经部署后,她还是想到了这位父亲的问题。计算机运算越来越多地用于指导可能改变生活的决定,包括哪些人被指控犯罪后应该被拘留;哪些家庭可能存在虐童情况而需要调查,以及在所谓的“预测性警务”中,警察应当关注哪些社区。
这些工具能让决策更统一、精确、严谨。但对于它们的监管是有限的,谁都不知道有多少工具在使用中。比方说2016年,美国记者称有一套被用来评估未来犯罪活动风险的系统歧视黑人被告。
纽约大学研究中心——AI Now研究所的联合创办人Kate Crawford说:“最让我担心的是,我们用来改善问题的系统,却反过来使问题加剧了。”该中心主要研究人工智能对社会的影响。
Crawford和其他人的警告,促使政府开始着手让软件承担起更多责任。去年12月,纽约市议会通过了一项法案,成立一个工作组,专门就如何公开分享有关算法的信息以及进行偏见调查出谋划策。
今年,法国总统马克龙表示,法国政府将公开所有使用的算法。在本月发布的指导意见中,英国政府要求公共行业和数据打交道的部门都要做到透明、负责。5月底开始生效的GDPR(欧洲通用数据保护条例)也有望促进算法问责制。

Rhema Vaithianathan开发相关算法来标记潜在的虐童案件。来源:奥克兰理工大学
在这些活动中,科学家们面临着许多复杂的问题,总结来说就是,何为算法公平。像Vaithianathan这样的研究人员,在公共机构工作,他们在开发负责、高效的软件时,必须努力解决自动化工具可能带来的偏见或加剧现有不公平现象的问题——尤其是这些工具用在本就存在歧视的社会系统中时。
犹他大学的理论计算机科学家Suresh Venkatasubramanian指出,自动决策工具引发的问题并非新闻。用于评估犯罪或信用风险的精算工具已经存在数十年,但随着大型数据集和复杂模型越来越普及,人们无法再忽视这些工具的伦理影响。“计算机科学家别无选择,只能参与其中。我们不能再像以前一样,把算法丢出去,不管不顾。”
公平交换
2014年,当匹兹堡所在的阿利根尼县人力服务部门提议用自动化工具时,还没有决定如何使用,但他们知道,他们想要公开透明。该部门数据分析、研究和评估办公室副主任Erin Dalton说:“我非常反对用政府的钱做黑箱解决方案,而不能告诉我们的社区我们正在做什么。”
这个部门有一个1999年建的中央数据仓库,里面存着大量个人信息——包括住房、心理健康和犯罪记录。Dalton说,Vaithianathan的团队非常注重儿童福利。
AFST(阿利根尼县家庭筛查工具)创建于2016年8月,热线每接到一个电话,呼叫中心的人员都能看到自动风险评估系统生成的得分,分数在1-20之间,20代表最高风险,也就是AFST预测孩子将在两年内被带走的家庭,或孩子被疑遭虐待而被再次转接到该县的家庭(现在该县正在逐步放弃第二个指标,因为这一指标未能精准反映需要进一步调查的案例)。
加州斯坦福大学的独立研究人员Jeremy Goldhaber-Fiebert仍在评估这一工具。但Dalton表示,初步结果表明该工具是有帮助的。在呼叫中心工作人员提交给调查人员的案例中,理由合理的情况更多了。对于情况类似的案例,筛查人员的判断似乎前后更一致了。当然了,他们的判断并不一定吻合算法的风险得分,该县希望能使二者进一步统一起来。
伴随着AFST的部署,Dalton希望得到更多帮助,来判断它是否存在偏见。2016年,Dalton邀请卡内基梅隆大学的统计学家Alexandra Chouldechova来分析该软件是否歧视特定群体。Chouldechova之前已经在思考算法中的偏见,正准备就该话题引发的广泛讨论发表自己的意见。
当年5月,新闻网站ProPublica的记者报道了佛罗里达州法官使用商业软件来帮助决定被控犯罪的人是否应该在审判前释放。这款叫做COMPAS的软件的作用是:预测一个人如果被释放,在接下来两年内再次犯罪的可能性,进而生成相应得分。记者称该软件对黑人被告存有偏见。
ProPublica团队调查了数千名被告的COMPAS得分,并将黑人和白人被告的相对比,发现许多黑人被告是“假阳性”:他们被COMPAS归类为高风险人群,但之后并未被指控犯其它罪行。
开发该算法的密歇根公司Northpointe(也就是现在俄亥俄州的Equivant)称,COMPAS不存在偏见,在预测被归类为高风险的白人或黑人被告会否再次犯罪方面(所谓“预测性平等”概念的一个例子),这款工具同等有效。
Chouldechova很快表明,Northpointe和ProPublica对公平的度量存在偏差。预测性平等、相等的假阳性错误率以及相等的假阴性错误率都是“公平”的方式,但如果两个组别之间存在差异——例如白人和黑人被再次逮捕的比率,那么在统计上就无法调和。
伦敦大学学院负责机器学习的研究员Michael Veale说:“鱼和熊掌不能兼得。如果你想实现这种方式的公平,那么从另一个角度看未必公平,虽然另一个角度也很合理。”
如何定义“公平”
研究算法偏见的研究人员表示,定义公平的方式很多,有时候还相互矛盾。
想象在刑事司法系统中使用的一套算法,根据再次被逮捕的风险,给两组对象(蓝色和紫色)生成得分。历史数据显示,紫色一组的逮捕率较高,所以算法模型会把更多紫色组的人归类为高风险(如图所示)。即使模型开发人员试图通过不直接告诉模型谁是蓝色组人,谁是紫色组人来避免偏见,但偏见还是可能发生。那是因为,用于训练中的其它数据可能暗示了某个人属于哪一组。
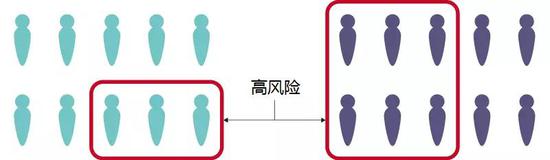
高风险状态并不能完美预测再次逮捕,但算法开发人员想要让预测更公平:对于两组人来说,“高风险”等同于两年内被再次逮捕的概率为2/3。(这种公平性被称为预测性平等。)未来逮捕的比例可能不会遵循过去的模式。
但在这个简单的例子中,假设未来逮捕与过去模式相同,那么:如预测的那样,蓝色组10个人当中的3个和紫色组10个人当中的6个(以及每组被标记为高风险中的2/3的人)会被再次逮捕(图中带灰色竖条的)。
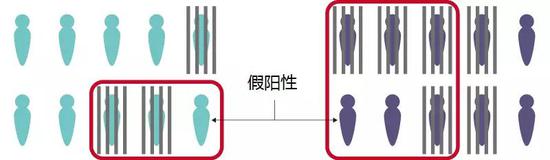
该算法确实实现了预测性平等,但有个问题。在蓝色组中,7个人中的1个(14%)被误列为高风险;在紫色组中,4个人中的2个(50%)被误列为高风险。因此,紫色组更容易出现“假阳性”:也就是被列为高风险。
只要蓝色组和紫色组成员的重新逮捕率不同,那么就很难实现预测性平等和相等的假阳性率。从数学上也不可能在实现这一点的同时,满足第三个公平度:相等的假阴性率(被列为低风险但再次被逮捕的人;在上述例子中,蓝色组和紫色组的这一概率恰巧相等)。
有人会认为,紫色组假阳性率较高是歧视。但其他研究人员认为,这并不能证明算法存在偏见。并且,这一不平衡可能由更深层的原因导致:紫色组可能从一开始就被不公平地当作逮捕目标。算法根据过去的数据准确预测紫色组被重新逮捕的人数更多,这可能是算法在重现——或巩固——早已存在的社会偏见。
事实上,从数学角度来说,还有更多定义公平的方法:在今年2月的一次会议上,计算机科学家Arvind Narayanan发表了题为“21种公平定义及其政治学”的演讲,并且他指出还有其它定义。
一些调查过ProPublica案例的研究人员(包括Chouldechova)表示,不相等的错误率是否反映偏见还不明确。相反,斯坦福大学的计算机科学家Sharad Goel认为,它们反映的是一个群体比另一个群体更难预测。“事实证明,这多多少少是一种统计假象。”
对于一些人来说,ProPublica案例突出了这样一个事实,即许多机构缺乏资源来正确评估算法工具。 “如果(这个案例)说明了什么的话,那就是聘请Northpointe的政府机构没有给他们一个明确的公平定义。”
芝加哥大学数据科学和公共政策中心主任Rayid Ghani说道,“我认为政府需要学习、接受培训以了解如何使用这些系统,如何定义他们所应衡量的指标,确保供应商、顾问和研究人员所给的系统是公平的。”
阿利根尼县的经验表明了解决这些问题是多么困难。当Chouldechova按照要求于2017年年初开始挖掘该县的数据时,她发现她的工具也遇到了类似的统计失衡。她说该模型有一些“非常不合需要的特性”,在种族和族群中的错误率差异比预期高很多。
另外,由于未知原因,在同样得到最高风险得分的情况下,被虐待的白人儿童转移率要低于黑人儿童。阿利根尼和Vaithianathan的团队目前正在考虑转向另一种模型。Chouldechova说,新模型可能有助于减少不公平现象。
尽管统计失衡是一个问题,但算法中潜藏着更深的危险——即它们可能会加剧社会不公正。举例来说,诸如COMPAS之类的算法,其开发初心是预测未来犯罪活动的可能性,但它依赖于可度量的指标,例如被被捕。
而警务的差异可能意味着,某些社区不相称地被警方列为重点监控目标,因而在其它社区可能被忽视的罪行,在这些社区却会被逮捕。
华盛顿特区非营利性社会公正组织Upturn的董事总经理David Robinson表示:“即使我们能够准确预测什么事情,我们所预测的事情也可能是不公正的。”在很大程度上,公正取决于法官依赖这些算法做决定的程度——而这一点我们知之甚少。

新泽西州警方使用自动工具来帮助确定哪些区域需要巡逻。来源:Timothy Clary/AFP/Getty
阿利根尼县的工具受到了类似的批评。作家兼政治学者Virginia Eubanks认为,无论算法是否准确,它所依赖的都是有偏见的数据,因为黑人和种族混合家庭被报告的几率更大。此外,由于算法依赖阿利根尼县系统中的公共服务信息——并且因为使用此类服务的家庭通常很贫困——因此算法使他们要受到更严格的审查,事实上这是一种不公平的惩罚。
Dalton承认缺乏可用数据是一种限制,但这个工具还是必要的。今年早些时候,阿利根尼县在AFST网站上回应Eubanks说:“不幸的社会贫困问题并不能否认我们有责任提高决策能力,服务于那些孩子。”
透明度及其限制
虽然有一些机构会开发自己的工具或使用商业软件,但学术界发现需要开发一些服务公共部门的算法。芝加哥大学的Ghani一直在和许多部门——包括芝加哥公共卫生部门合作,开发用于预测哪些房屋可能含有有毒铅的工具。
在英国,剑桥大学的研究人员与达勒姆县的警察合作建立了一套模型,帮助确定谁适用干预计划,而不用起诉。今年,Goel和他的同事成立了斯坦福计算政策实验室,正在与包括旧金山地方检察官办公室在内的政府机构合作。
该办公室的分析师Maria McKee表示,与外部研究人员合作至关重要。“我们都知道什么是正确的,什么是公平的,”她说,“但经常没有工具或研究来准确、系统地告诉我们如何实现。”
人们对提高透明度的需求很大,阿利根尼县采取开放的政策,让利益相关者参与其中,对记者常开大门。AI Now研究所的Crawford说,当算法“是一个闭环,无法进行审计、审查或公开讨论”时,通常会加剧问题。但目前还不清楚应当以何种方式使算法更开放。
Ghani说,简单地发布模型的所有参数并不能使相关人员了解算法的运作方式,透明度也可能与保护隐私相冲突。在某些情况下,透露过多算法运作信息还有可能导致系统被操纵。
Goel坦言,问责制的一个重大障碍是,机构通常不会收集有关工具使用方式或性能的数据。“很多时候没有透明度可言,因为没什么可分享的。”
比方说,加州立法机构有一项草案,要求风险评估工具帮助减少被告必须支付保释金的频率——这种做法一直受到批评,因为它是对低收入被告的一种惩罚。Goel希望该法案规定,只有当法官与工具决策及特定细节——包括判决结果意见相左时才能收集数据,每一件案子都是如此。
“我们的目的是从根本上减少监禁,同时维护公共安全,”他说,“所以我们必须要知道——这套工具有用吗?”
Crawford表示,我们需要一系列“法定程序”来确保算法负责。今年4月,AI Now 研究所为有意负责任地采用算法决策工具的公共机构搭建了一个框架;此外,它还呼吁征求公众意见,并让人们能够对算法做出的决策提出上诉。
许多人希望法律能够实现这些目标。Solon Barocas是康奈尔大学研究人工智能伦理与政策问题的研究员,他说这方面早有一些先例。Veale说,美国的一些消费者保护条例在对消费者信用做出不利判定时会给予解释;早在上世纪70年代,法国就有赋予公民解释权和反驳自动化决策的立法。
不过,最大的考验还是5月25日生效的欧洲GDPR。GDPR的一些条款——如赋予用户了解自动化决策案例中涉及的逻辑信息的权利——似乎可以促进算法问责制。
但英国牛津互联网研究所的数据伦理学家Brent Mittelstadt表示,GDPR或许为那些想要评估公平性的人创造了一个“合法雷区”,进而阻碍算法问责制的发展。
要测试一种算法是否存在偏见(例如是否偏袒某一种族),最佳方法是了解进入系统的人的相关特征。但Mittelstadt表示,GDPR对使用此类敏感数据的约束非常严厉,惩罚很高,因此有能力评估算法的公司可能没有动力处理这些信息。“这似乎会对我们评估公平性能力造成限制。”Mittlestadt说。
GDPR条款能在多大程度上让公众了解算法并对决策进行上诉,也还是个问题。如上所述,一些GDPR条款仅适用于完全自动化的系统,也就是说,受算法影响、但最终决策权在人类手中的情况被排除在外。Mittelstadt说,相关细节最终应该在法庭上澄清。
审查算法
与此同时,针对尚未开放供公众审查的算法,研究人员也在提出各种检测偏见的策略。Barocas认为,企业可能不愿意讨论他们是如何努力解决公平问题的,因为这意味着首先你要承认存在问题。
而即便他们愿意讨论,其措施也可能是缓解偏见,但无法消除偏见。“所以任何关于这一话题的声明,都将不可避免地承认问题仍然存在。”不过,最近几个月,微软和Facebook都宣布将开发检测偏见的工具。
一些研究人员,如波士顿东北大学的计算机科学家Christo Wilson,试图从外部发现商业算法的偏见。比方说,Wilson创建了叫Uber的虚拟乘客,又将虚拟简历上传到求职网站,检测是否存在性别偏见。
其他研究人员也都在开发相关软件,希望可以用于一般的自我评估。今年5月,Ghani和他的同事发布了名为Aequitas的开源软件,帮助工程师、决策者和分析师审查机器学习模型的偏见;一向对算法决策危险性直言不讳的数学家Cathy O‘Neil也成立了一家公司,和企业进行私下合作,审查它们的算法。
一些研究人员呼吁在刑事司法应用和其他领域退后一步,不要只专注开发预测算法。算法工具或许善于预测谁不会出庭,但是搞清楚人们为何不出庭,或者设计干预方式,例如发短信提醒或安排交通,帮助提高出庭率,岂不更好?
“这些工具常做的是修修补补,但我们需要的是全面的改变。”纽约大学法学院民权律师和种族平等倡导者Vincent Southerland说道。他认为围绕算法的激烈辩论“迫使我们所有人都要开口,就我们正在使用的系统及其所运行的方式提出一些非常严肃的基本问题,并做出回答”。
Vaithianathan现在正致力于将她的虐童预测模型推广到科罗拉多州道格拉斯县和拉里默县,即使模型所嵌入的总体系统存在缺陷,但她依然能够看到优化算法的价值。即便如此,她说“不能冒冒失失地将算法丢入复杂系统中”,必须有了解大背景的人帮助才能落实。
即便是最优的算法也会面临挑战,因此,在缺乏直接答案和完美解决方案的情况下,保证透明度是最好的办法。“我总是说:如果做不到正确,至少要诚实。